
Los programas electorales
Los partidos políticos basan su discurso, supuestamente, en la línea definida en sus programas electorales. En teoría, los programas electorales deberían ser los contratos que los partidos políticos firman con los ciudadanos, aunque en la práctica eso no ocurre. Nosotros no vamos a entrar a valorar cuánto realismo hay en los programas de los partidos, ni si una vez elegidos los representantes e investidos los presidentes ( ) los programas se cumplen, por ahora. Lo que vamos a hacer es analizar los programas electorales desde un punto de vista separado de cualquier sesgo político.
) los programas se cumplen, por ahora. Lo que vamos a hacer es analizar los programas electorales desde un punto de vista separado de cualquier sesgo político.
Los programas electorales, en la mayoría de los casos, son documentos de texto y como texto se pueden analizar. Se puede empezar con el análisis más sencillo (considerando sólo sus palabras como átomos aislados) hasta llegar a análisis avanzados de sentimiento positivo/negativo o polaridad del discurso encerrado en cada frase o sección. Entre lo básico y lo avanzado hay unos cuantos métodos interesantes, y es lo que vamos a tratar de explicar en éste y otros posts relacionados.
¿Cómo se hace todo esto? Todo esto no es ni más ni menos que una de las múltiples aplicaciones del Procesamiento del Lenguaje Natural (NLP – Natural Language Processing) y se hace a través de técnicas y métodos de Aprendizaje Automático (Machine Learning) alimentados por datos. De hecho, cuantos más datos mejor.
¿Dónde están los datos?
Las palabras son nuestros datos, así de simple. Podemos ver las palabras como secuencias de letras, o convertirlas en números dependiendo del tipo de análisis, pero las palabras son definitivamente nuestros datos.
Frases están formadas por palabras, párrafos por frases, secciones de programas por párrafos hasta que finalmente el programa es una lista de secciones.
Partidos políticos a analizar
Esperamos que nadie se sienta agraviado: insistimos, este ejercicio no es un ejercicio de análisis político.
Tenemos que decidir qué analizamos, así que hemos decidido analizar el contenido de los programas de los 5 partidos políticos con mayor representación parlamentaria tras las últimas elecciones generales del 28-A: PSOE, PP, Cs, UP y VOX.
Vayamos al grano
Los programas electorales pueden tener una introducción para contextualizar lo que viene a continuación y un cierre recapitulando su contenido. Hemos decidido prescindir de las partes inicial y final para quedarnos con las secciones que definen el programa: los puntos programáticos.
La buena noticia es que los puntos programáticos son algo en lo que todos los partidos coinciden a la hora de organizar sus programas, así que también facilita la labor de análisis. Comencemos!
Ciudadanos (Cs) es el único partido para el que no hemos encontrado un documento formal de programa, sino que cuenta con una página web donde se detalla (aquí). Existe una versión de fácil lectura (aquí), pero cuenta con muy poco contenido. La línea programática de Cs se resume en 14 puntos:
- La España de ciudadanos libres e iguales
- Tolerancia cero con la corrupción
- Una economía moderna y competitiva para ganar el futuro
- Empleo del siglo XXI- un nuevo modelo laboral que ponga fin a la precariedad
- La educación, en el centro
- Turismo, cultura y deporte- poner en valor nuestro liderazgo
- Convertir España en el mejor país del mundo para las familias
- Una sanidad pública de calidad que garantice la igualdad
- Liderar la España del S.XXI- más libertad, más igualdad, más modernidad
- Cuidar nuestro país para nuestros hijos y nuestros nietos
- Un compromiso del Estado para combatir la despoblación
- Vivienda, infraestructuras y movilidad- políticas efectivas y sensatas
- Una política de Seguridad y Defensa adaptadas al siglo XXI
- Una España líder en una Europa más unida
El PP no parece haber elaborado un documento específico para las elecciones del 10-N, sino que nos remite en su directorio de programas (aquí) a un documento de 2019 que incluye su línea programática (aquí), y que se resume en 10 puntos:
- Comprometidos con el fortalecimiento de la nación
- Una revolución fiscal para el crecimiento económico y la competitividad
- Por una economía moderna y avanzada
- Por una educación de calidad y en libertad
- Más y mejor sociedad del bienestar
- Familia. Políticas sociales para la igualdad de oportunidades
- Más oportunidades para las personas
- Una España sostenible con futuro
- Una mejor democracia
- Retos globales de una sociedad abierta
El PSOE ha colgado en su página oficial (aquí) un documento específico con su programa completo para las elecciones del 10-N. Este documento se puede encontrar aquí. En él, se ha estructurado su línea programática en 6 puntos:
- Empleo justo y pensiones dignas
- Feminismo, lucha contra la desigualdad social y calidad democrática
- Emergencia climática y transición ecológica de la economía
- Avance científico, tecnológico y transición digital
- Estructura territorial
- España en Europa, España en el mundo
En el caso de UP sí hay un documento específico y completo para el 10-N (aquí), cuya línea programática se resume en 8 puntos:
- Horizonte Verde y Nuevo Modelo Industrial
- Horizonte Morado y Economía de los Cuidados
- Horizonte Digital y Nueva Economía
- Garantías Democráticas y de Ciudadanía
- Garantías de Justicia Laboral y Pensiones
- Garantías de Justicia Social
- Garantías de Justicia Fiscal
- Garantías de Justicia Territorial
En la página de programa electoral de VOX (aquí) no hemos encontrado una referencia expresa al 10-N en el programa que se publica (aquí). Este programa se desglosa en 10 puntos:
- España, unidad y soberanía
- Ley electoral y transparencia
- Inmigración
- Defensa, seguridad y fronteras
- Economía y recursos
- Salud
- Educación y cultura
- Vida y familia
- Libertades y justicia
- Europa e internacional
¿Qué hacemos con todo esto?
Ahora viene un poco de albañilería para poder disponer de nuestros datos (palabras). Hay muchas formas de hacer disponible la información para que se puedan utilizar las técnicas NLP. Nosotros hemos optado por una forma simple y que todo el mundo puede hacer: almacenar en un fichero de texto diferente (.txt) cada punto del programa de cada partido político.
Hay herramientas online que fácilmente convierten un fichero pdf o una página HTML en un fichero de texto. Con ese fichero pdf/HTML por partido político, el único trabajo «manual» que hemos hecho ha sido cortar cada punto programático y almacenarlo en un fichero individual. Se acabó el trabajo manual: no hay que volver a tocar los ficheros nunca más: – ¿ni para limpiarlos de caracteres extraños? Ni para limpiarlos de caracteres extraños. De eso ya se encargarán nuestros métodos.
Ficheros de programas por partido
Para todos aquellos que quieran hacer sus propios análisis con los ficheros de los programas políticos, aquí tenéis un fichero zip con las secciones programáticas por partido.
Procesamiento de los programas electorales
Ahora que tenemos los ficheros de los programas electorales en crudo, podemos procesarlos siguiendo una serie de pasos:
- Leer los ficheros, para formar un corpus y limpriarlo de caracteres extraños/no estándar. En este post explicamos el proceso.
- Dividir el corpus en palabras, ya que es la unidad que queremos utilizar para el análisis. Aquí hay un post que habla de ello.
- Limpiar el corpus de palabras vacías de significado, para dejarlo sólo con aquellas palabras que aportan. Aquí lo vemos.
Primer análisis: contar palabras
Aunque pueda parecer básico, un simple conteo de las palabras totales vs. palabras útiles del programa de cada partido nos puede dar alguna información interesante. Recordemos que las palabras útiles son las que aportan significado y para quedarnos con ellas simplemente hemos eliminado las stop words de nuestro corpus que contiene los programas electorales.
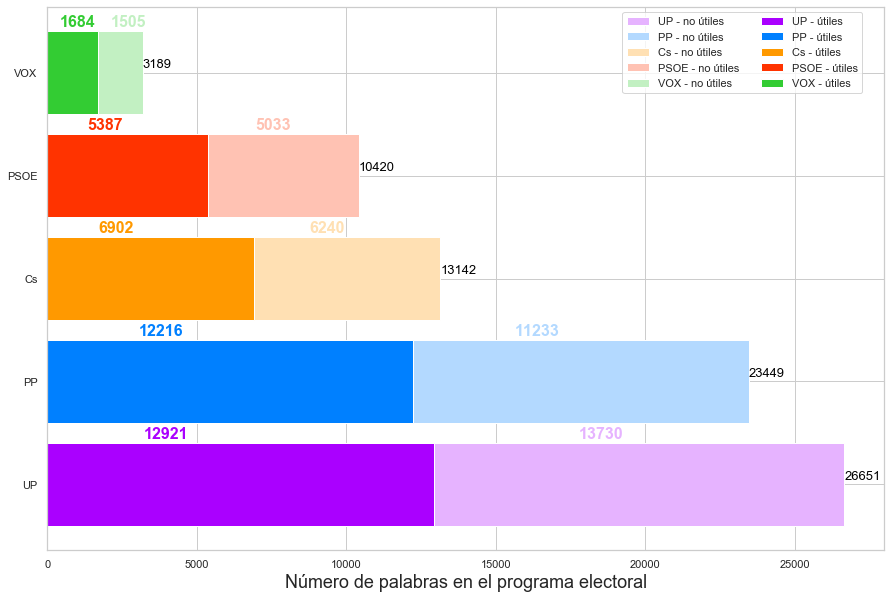
En el gráfico de abajo podemos ver cuántas palabras contienen los programas electorales de cada partido: desde las 3189 palabras de VOX a las 26651 palabras de UP. Las conclusiones las sacáis vosotros, nosotros sólo mostramos las diferencias y semejanzas que hay entre los diferentes partidos.
Un poco de lupa: ratio de palabras útiles
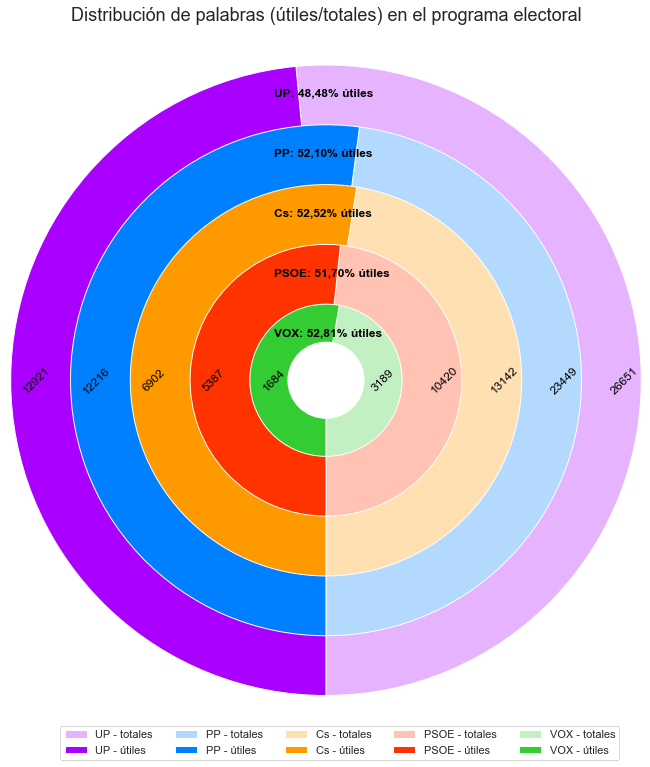
En la sección anterior podíamos ver de una forma más o menos clara cómo se repartía el porcentaje de palabras útiles respecto al total de palabras del programa de cada partido. Si lo visualizamos en forma de «donut», el resultado nos dice que el porcentaje va del 48,48% de palabras útiles de VOX al 52,81% de palabras útiles de UP.
Los datos crudos
Como referencia, podemos ver los números en crudo:
| Palabras totales | Palabras útiles | |
| Cs | 13142 | 6902 |
| PP | 23449 | 12216 |
| PSOE | 10420 | 5387 |
| UP | 26651 | 12921 |
| VOX | 3189 | 1684 |
Si te interesa el código, aquí lo tienes
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 |
import pandas as pd import string import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns import os from os import listdir from os.path import isfile, join import spacy from spacy.tokens import Doc import re import nltk from nltk.tokenize import RegexpTokenizer from nltk.corpus import stopwords nltk.download('stopwords') nltk.download('wordnet') # Function to return a list of stop words to consider def create_stop_words(): # We create a stop word list stops = set(stopwords.words("spanish")) # We define individual numbers and letters as stop words all_letters_numbers = string.digits + string.ascii_letters stops = stops.union([]) # add some stopwords stops = stops.union(list(all_letters_numbers)) return stops g_parties_dict = {"Cs": "./Programas/Cs/", "PP": "./Programas/PP/", "PSOE": "./Programas/PSOE/", "UP": "./Programas/UP/", "VOX": "./Programas/VOX/"} g_parties_color_dict = {"Cs": ["#ffe0b3", "#ff9900"], "PP": ["#b3d9ff", "#0080ff"], "PSOE": ["#ffc2b3", "#ff3300"], "UP": ["#e6b3ff", "#aa00ff"], "VOX": ["#c2f0c2", "#33cc33"]} g_nlp = spacy.load('es_core_news_sm') g_stop_words = create_stop_words() | g_nlp.Defaults.stop_words g_not_category_name='Resto de partidos' g_charts_root_dir = './Charts' def list_dirs(directory): """Returns all directories in a given directory """ return [f for f in pathlib.Path(directory).iterdir() if f.is_dir()] def list_files(directory, ext): """Returns all files in a given directory """ onlyfiles = [join(directory, f) for f in listdir(directory) if isfile(join(directory, f)) and f.endswith(ext)] return sorted(onlyfiles) # Function to remove numbers and small words (1 or 2 letters) from a document def num_and_short_word_preprocessor(tokens): # Regular expression for numbers no_numbers = re.sub('(\d)+', '', tokens.lower()) # Regular expression for 1-letter and 2-letter words no_short_words = re.sub(r'\b\w{1,2}\b', '', no_numbers) return no_short_words # Function to tokenize a document wihthout using stopwords def custom_tokenizer(doc): word_tokenizer = RegexpTokenizer(r'\w+') tokens = word_tokenizer.tokenize(doc) return tokens # Function to tokenize a document using stopwords def custom_tokenizer_filtering_stopwords(doc): word_tokenizer = RegexpTokenizer(r'\w+') tokens = word_tokenizer.tokenize(doc) filtered_tokens = [token for token in tokens if token not in g_stop_words] return filtered_tokens def create_Doc(row): doc = Doc(g_nlp.vocab, words=row) doc.is_parsed = True return doc def create_party_programs_corpus_with_sections(): all_party_program_section_name_l = [] all_party_corpus_lc = [] all_party_name = list() for party_name, party_program_location in g_parties_dict.items(): # List of files and their corresponding names that make up the party program party_program_section_file_l = list_files(party_program_location, ".txt") party_program_section_name_l = list(map(lambda x: os.path.split(x)[1], party_program_section_file_l)) # List that contains the program document corpus party_program_corpus = list() # Fill out the corpus for section_file_name in party_program_section_file_l: with open(section_file_name, 'r', encoding="utf8") as section_file: section_file_data = section_file.read().replace('\n', '. ') party_program_corpus.append(section_file_data) all_party_name.append(party_name) # Clean up sections party_corpus_lc = [section.lower() for section in party_program_corpus] # to lowercase party_corpus_lc = [re.sub("(\d)+", '', section) for section in party_corpus_lc] # no numbers party_corpus_lc = [re.sub("[€º”—“«»>•‘’!""#$%&'()*+,-./:;?@[\]^_`{|}~]+", ' ', section) for section in party_corpus_lc] # no strange characters party_corpus_lc = [re.sub('\s\s+', ' ', section) for section in party_corpus_lc] # no multiple spaces party_corpus_lc = [re.sub(r'\b\w{1}\b', '', section) for section in party_corpus_lc] all_party_corpus_lc += party_corpus_lc # Cleanup section names all_party_program_section_name_l += party_program_section_name_l all_party_program_section_name_l = [re.sub(".txt", '', section_name) for section_name in all_party_program_section_name_l] all_party_program_section_name_l = [re.sub("(\d)+[-]", '', section_name) for section_name in all_party_program_section_name_l] token_raw_party_section = [custom_tokenizer(section) for section in all_party_corpus_lc] token_filtered_party_section = [custom_tokenizer_filtering_stopwords(section) for section in all_party_corpus_lc] # Create DataFrame party_corpus_df = pd.DataFrame(data = { "Party": all_party_name, "Section_name": all_party_program_section_name_l, "Section_text": all_party_corpus_lc, "Tokenized_raw_section_text": token_raw_party_section, "Tokenized_filtered_section_text": token_filtered_party_section, }) parsed = party_corpus_df.Tokenized_filtered_section_text.apply(create_Doc) party_corpus_df["Parsed_section_text"] = parsed return party_corpus_df def get_word_breakdown(party_corpus_df): def get_num_tokens(values): flat_list = [item for sublist in values for item in sublist] return len(flat_list) total_words = party_corpus_df.groupby("Party").Tokenized_raw_section_text.agg(get_num_tokens) useful_words = party_corpus_df.groupby("Party").Tokenized_filtered_section_text.agg(get_num_tokens) words_per_party = pd.DataFrame(total_words).assign(x=useful_words.values) words_per_party.reset_index(level=0, inplace=True) words_per_party.columns = ['Party', 'Total words', 'Useful words'] return words_per_party def create_wordcount_pie(words_per_party): import locale locale.setlocale(locale.LC_NUMERIC, 'es_ES') words_per_party = words_per_party.sort_values(by=['Total words'], ascending=False).reset_index(drop=True) legends_l = [] for party in words_per_party['Party']: legends_l.append("{} - totales".format(party)) legends_l.append("{} - útiles".format(party)) sns.set(color_codes=True) sns.set_style("whitegrid") figure = plt.figure(figsize=(10, 5)) ax_pie = figure.add_subplot(1, 1, 1) startingRadius = 1.7 + (0.3* (len(words_per_party)-1)) for index, row in words_per_party.iterrows(): party_name = row["Party"] total_words = row["Total words"] useful_words = row["Useful words"] useless_words = row["Total words"] - row["Useful words"] party_colors = g_parties_color_dict[party_name] useful_words_pct = (useful_words / total_words) * 100 localized_useful_words_pct = locale.format_string('%.2f', useful_words_pct, grouping=True) label_text = "{}: {}% útiles".format(party_name, localized_useful_words_pct) label_text_2 = "{}".format(total_words) remaining_pct = 100 - useful_words_pct donut_sizes = [remaining_pct, useful_words_pct] ax_pie.text(-0.48, startingRadius - 0.26, label_text, horizontalalignment='left', verticalalignment='center', fontsize=12, fontweight='bold',color='black') ax_pie.text(0.1 - startingRadius, 0, useful_words, horizontalalignment='left', verticalalignment='center', fontsize=12, fontweight='normal',color='black', rotation = 45) ax_pie.text(-0.3 + startingRadius, 0, total_words, horizontalalignment='left', verticalalignment='center', fontsize=12, fontweight='normal',color='black', rotation = 45) donut = ax_pie.pie(donut_sizes, radius = startingRadius, startangle = 270, colors=party_colors, labels = [total_words, useful_words], rotatelabels = False, counterclock = True, labeldistance = 0.95 - 0.025*index, wedgeprops = {"edgecolor": "white", 'linewidth': 1}, textprops = dict(rotation_mode = 'default', va='center', ha='center', rotation=45, wrap=True, #position=(2,0), visible=False ) ) startingRadius-=0.55 # create circle and place onto pie chart circle = ax_pie.add_patch(plt.Circle(xy=(0, 0), radius=0.35, facecolor='white')) horiz_offset = 1.6 vert_offset = -0.75 _ = ax_pie.legend(legends_l, bbox_to_anchor=(horiz_offset, vert_offset), ncol=5) _ = ax_pie.set_title('Distribución de palabras (útiles/totales) en el programa electoral', fontsize=18, x=0.5, y=1.8) def create_wordcount_stacked_bar(words_per_party): words_per_party = words_per_party.sort_values(by=['Total words'], ascending=False).reset_index(drop=True) sns.set(color_codes=True) sns.set_style("whitegrid") figure = plt.figure(figsize=(15, 10)) ax_1 = figure.add_subplot(1, 1, 1) parties = words_per_party["Party"] total_words_colors = [g_parties_color_dict[key][0] for key in parties.values] useful_words_colors = [g_parties_color_dict[key][1] for key in parties.values] total_words_legends = ["{} - no útiles".format(key) for key in parties.values] useful_words_legends = ["{} - útiles".format(key) for key in parties.values] useless_words = words_per_party["Total words"] - words_per_party["Useful words"] pie_1 = ax_1.barh(parties, words_per_party["Total words"], color=total_words_colors) pie_2 = ax_1.barh(parties, words_per_party["Useful words"], color=useful_words_colors) for i, v in enumerate(words_per_party["Total words"]): plt.text(v/1.5, i + .45, str(useless_words[i]), color=total_words_colors[i], fontweight='bold', fontsize=16) plt.text(v/1.0, i + .05, str(v), color='black', fontweight='normal', fontsize=13) for i, v in enumerate(words_per_party["Useful words"]): plt.text(v/4, i + .45, str(v), color=useful_words_colors[i], fontweight='bold', fontsize=16) # we also need to switch the labels ax_1.set_xlabel('Número de palabras en el programa electoral', fontsize=18) horiz_offset = 0.98 vert_offset = 1 _ = ax_1.legend(pie_1 + pie_2, total_words_legends + useful_words_legends, bbox_to_anchor=(horiz_offset, vert_offset), ncol=2) party_corpus_df = create_party_programs_corpus_with_sections() words_per_party = get_word_breakdown(party_corpus_df) create_wordcount_pie(words_per_party) create_wordcount_stacked_bar(words_per_party) |
Takeaway
Los programas electorales contienen abundante información para los ciudadanos, sean votantes activos o no. Al margen de ideologías políticas, de los programas se pueden extraer datos que ayuden a compararlos e identificar dónde se parecen más o donde se diferencian.
En este post hemos hecho un ejercicio sencillo, contar palabras, y ya hemos identificado diferencias y semejanzas entre partidos políticos, además de conocer qué porcentaje de palabras aporta poco significado a un discurso.
Cabe destacar que ya hemos hecho buena parte del trabajo tedioso de lectura y limpieza del corpus para poder afrontar análisis más avanzados en futuros posts.
Ver en Kaggle